
Intelligence is finally rentable by the task. We are still buying it by the person.
Eight of your last ten prompts to a frontier model probably didn't need one. That translation, that simple search, that git command. You reached for the frontier model anyway and so did I, because we are swimming in a sea of subsidized token abundance and because the habit is hard to unlearn.
Think of your last ten if you don't believe me. My guess is that one or two genuinely needed the best model you had access to. The other eight repeat a mistake we've been making about people for fifty years.
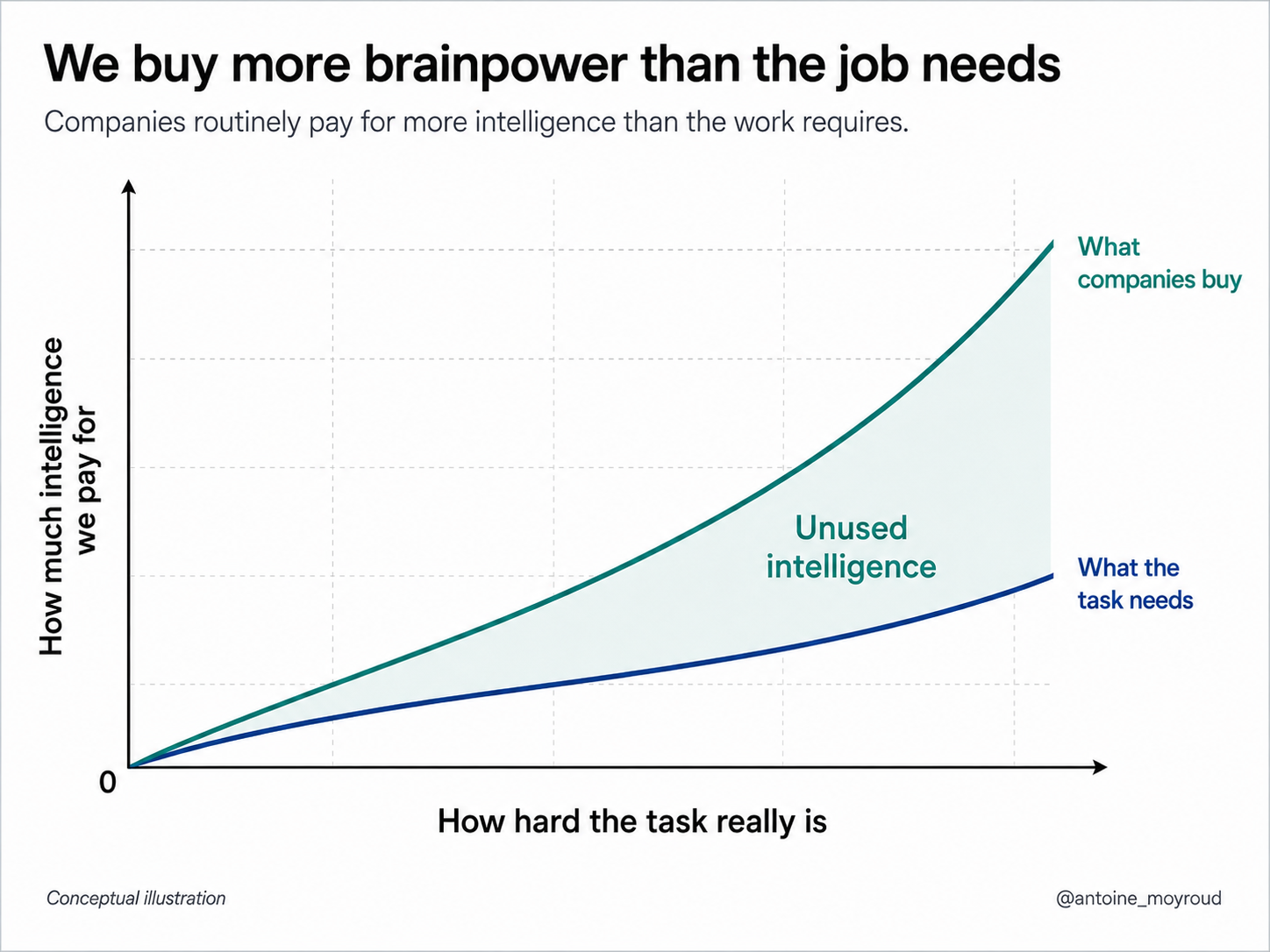
We over-provision intelligence because we can.
I am as guilty as anyone. I used to feel ridiculous routing basic git commands through a frontier model in Cursor. Now I just use whatever is sitting in my model router without thinking about it, even when the answer from an expensive model and a small open-source model would be the same.
It's a strange thing to do when you think about it. We're paying a premium for intelligence on tasks that clearly do not need it.
The more I sat with that, the more it looked less like an AI problem and more like something much older.
The PhD problem
Humans have always been bad at estimating how much intelligence a task actually requires.
You can see it everywhere in the labor market. Take credential inflation. The analyst doing Excel work today is not doing work that is categorically more intellectually demanding than the analyst doing Excel work thirty years ago.
The bar to get the job has climbed anyway.
More selective schools. More degrees. More proof that you are smart enough to do work that often does not require that level of smartness. Everyone has a master’s degree and the credential now means less precisely because everyone has one. When everyone is super, no one is.
Employers ask for more intelligence than the task requires because they can. Why deprive yourself of more capability if the market lets you have it?
The same thing happens inside a skilled employee’s week.
The PhD is not doing PhD-work most days. Some days she is solving the thing only she can solve and those days matter disproportionately. The reality is that a lot of the time she is writing updates, sitting in meetings, filling forms, moving information from one place to another.
You can't rent the version of her that cracks the hard problem for two hours and dismiss the version answering emails for the rest of the week. The employer is paying for her peak because the peak matters, so the employer buys the bundle.
That is the old constraint. Humans come bundled with their own range, from the strategic judgment down to the admin, from the rare insight to the routine follow-up. Every hire is a long position on someone’s entire distribution of capability, whether you use all of it or not.
That constraint shaped white-collar labor for a century.
Consultants, contractors, fractional execs, agencies, advisors, freelancers: all of them are attempts to work around the fact that intelligence could not be bought at the granularity of the task.
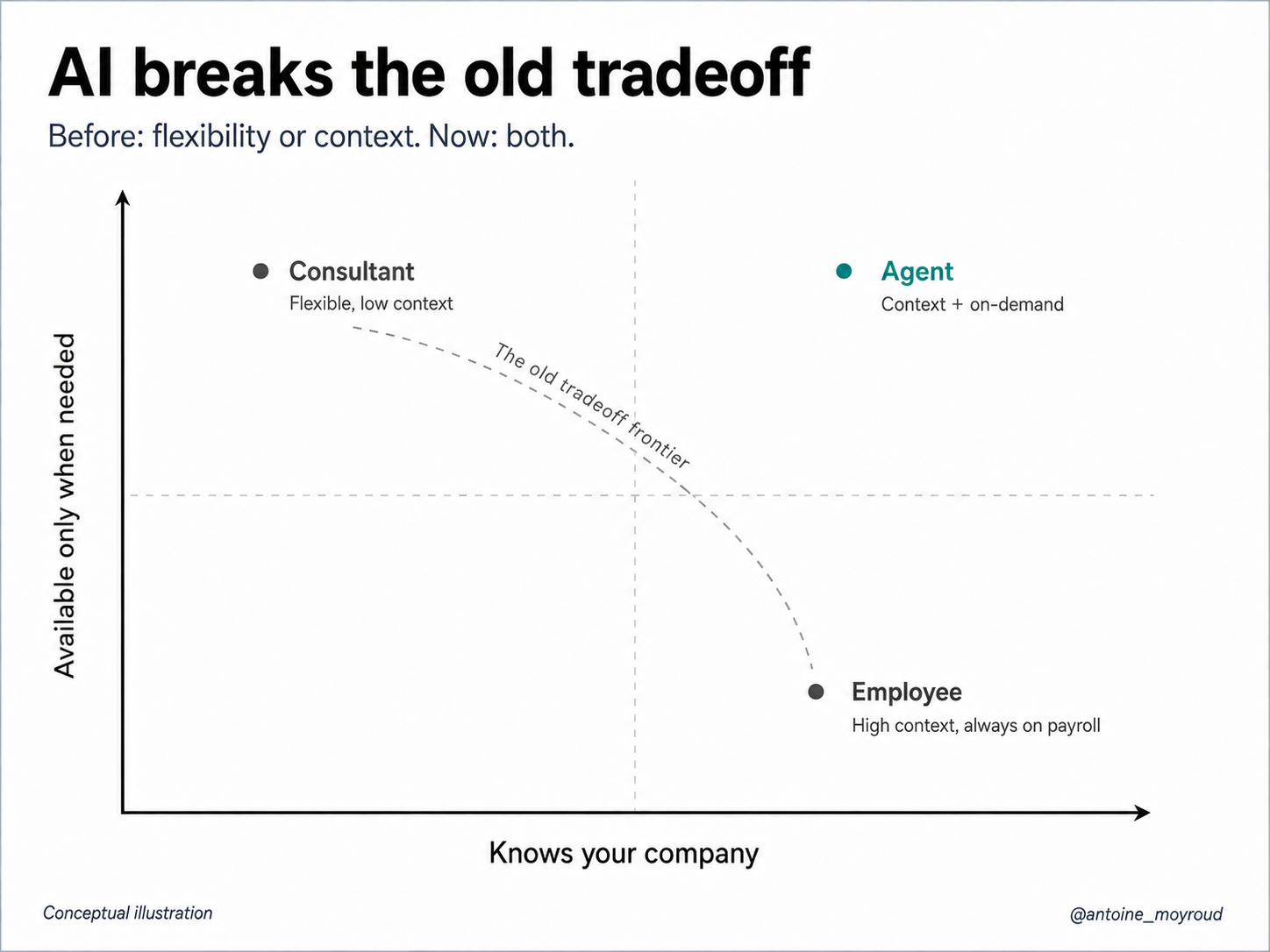
Every workaround had the same tradeoff. You could rent burst capability, or you could have someone who understood your business. Rarely both.
The contractor walks in with the skill but not the context. The employee has the context but is expensive to keep around for the moments when the skill is not needed (and maybe isn't as capable as the contractor). Spot intelligence and organizational memory sat at opposite ends of a tradeoff we were never able to solve. Until recently with agents.
The unbundling of intelligence
A model can hold your context, codebase, docs, customer history, your weird internal acronyms and the full state of the work.
Then you can summon it for a single task and dismiss it when the task is done. It has the contractor’s flexibility and the employee’s memory at the same time.
That is the big shift. Intelligence is now rentable by the task.
Not by the hour, the day rate or by the person. By the task.
I don't think we've fully internalized how strange that is. We've never lived in that world before. The entire modern company was designed around the opposite assumption: that intelligence comes attached to humans and humans have to be hired in whole units.
We built teams, budgets, workflows, reviews, headcount plans and org charts around bundled intelligence. Now the bundle is breaking.
Model routers are the most obvious early primitive of this new world. They dispatch easy prompts to a small fast model and reserve the expensive model for genuinely hard work.
Introducing model routing to Factory.
— Factory (@FactoryAI) June 2, 2026
Factory Router picks the right model for every task, automatically.
Maintain frontier performance while cutting costs by 25%. pic.twitter.com/WFnJbSnwNQ
It sounds like a technical optimization. I don't think it is. It may be framed as a feature today but, mark my words, this is the first step towards much deeper organizational reshuffling.
It's one of the first visible signs that the user shouldn't be responsible for deciding how much intelligence a task deserves.
Clem at Hugging Face made the adjacent point that having to choose a model creates too much friction, so most people default to the frontier model. If you remove the picker, value flows back toward smaller models because the decision to downgrade is no longer borne by the user.
For a century, the rational thing was to hire for the peak because you couldn't rent the peak. You hired the smartest person you could afford and then tolerated the fact that much of their week didn't require peak intelligence.
With AI, that changes, the question is no longer only: who owns this work? The question becomes: what level of intelligence should this task be allowed to spend?
This requires a very different type of organisational construct. Industrial work got much closer to this world than white-collar work ever did.
A factory line, in some sense, is the closest human civilization has come to decomposing work into tasks, measuring each one and asking which step can be optimized, automated, moved, simplified, or deleted.
Industrial companies have spent millions of hours and billions of dollars figuring out whether a specific movement, handoff or machine cycle could be improved.
Most white-collar work never went through this deep introspection phase.
The hiring contracts reflect it. In France, the cadre, an executive, is almost defined by the opposite assumption. Their week isn't broken down into tightly measured units of output, they are given autonomy over their time because we assume they're the best judge of how to allocate their own intelligence (which made sense when intelligence came bundled inside a person).
The goal was: hire someone smart and motivated, give them a goal and let them figure out the path. The work was too ambiguous, too varied and too hard to instrument. It also means most companies have no real map of their own cognitive workflows.
They know the job title, the team and the meeting cadence. They know the salary band. They often don't know, with any precision, what tasks actually consume the intelligence they're paying for.
Ask a non-technical PM to explain what their developers actually did this week, below the level of “backend stuff,” and you will understand why white-collar work resisted decomposition for so long 🙃.
My belief is that AI is going to force that mapping into existence.
It won't be because managers suddenly became Taylorists for white-collar work. It'll be because agents need a more explicit description of the work to be able to successfully participate in it. Once intelligence becomes available by the task, the company has to do the work to break down their org and work into a series of tasks.
The hedonic treadmill of intelligence
The problem is that people don't like to feel like they getting their toy taken away from them.
Once you've felt the strength of a frontier model, it's hard to dial back. Quinn Slack, who runs the coding agent Amp, calls this the hedonic treadmill of intelligence. I love that framing.
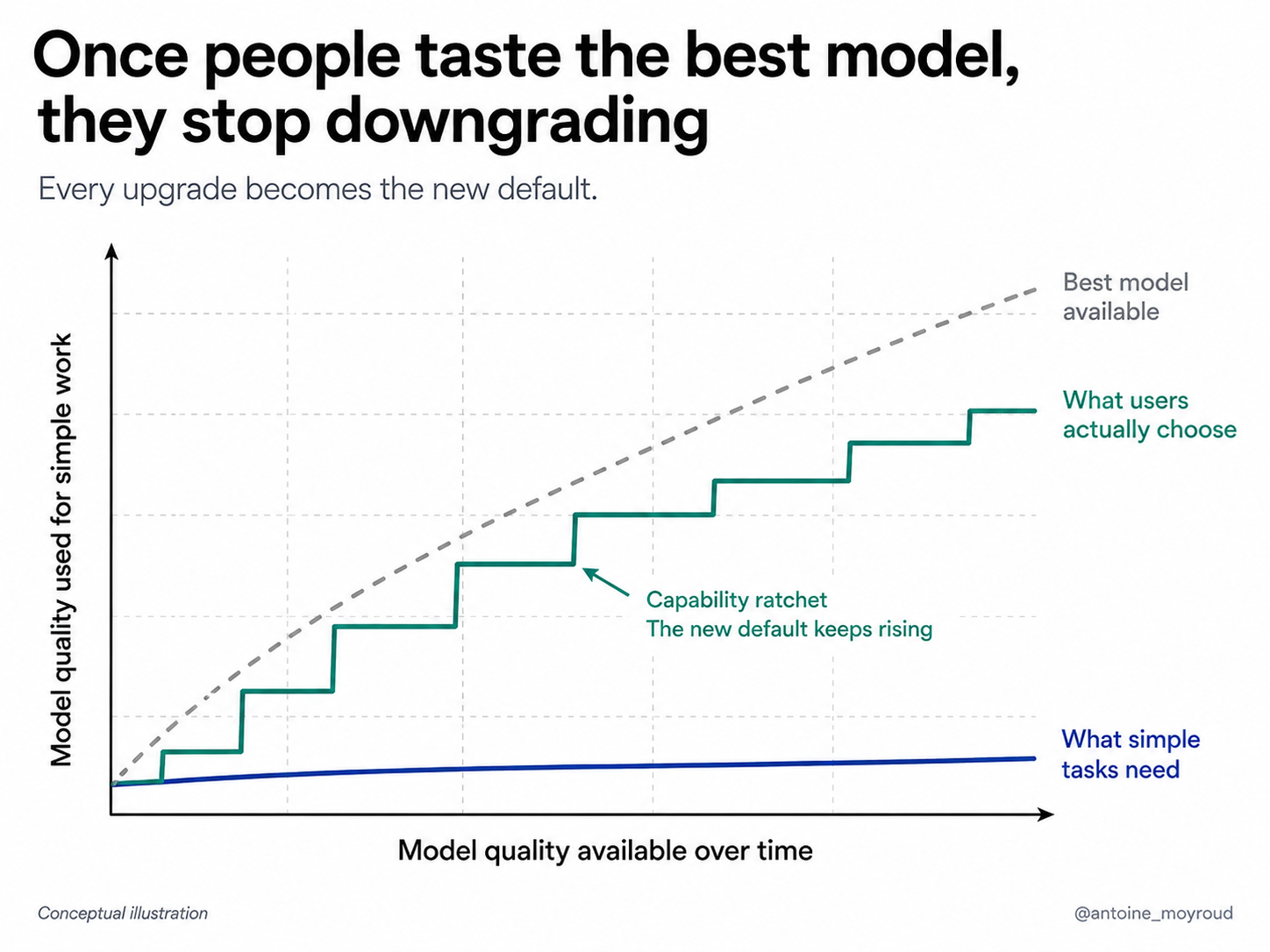
It's really hard to let go of "more capability" once that capability is available.
The same hiring manager who asks for the top-school graduate to do midwit spreadsheet work is now asking the frontier model to summarize a document.
Not because the task needs it but, as with hires, because the risk of under-provisioning feels worse than the cost of over-provisioning.
The hard part is knowing which tasks will go to sh*t when you downgrade. You need to benchmark, you need to iterate, it takes time. So most people do the opposite, they hedge upward and use the best model because the best model is there. It starts as something rational, then it becomes a habit.
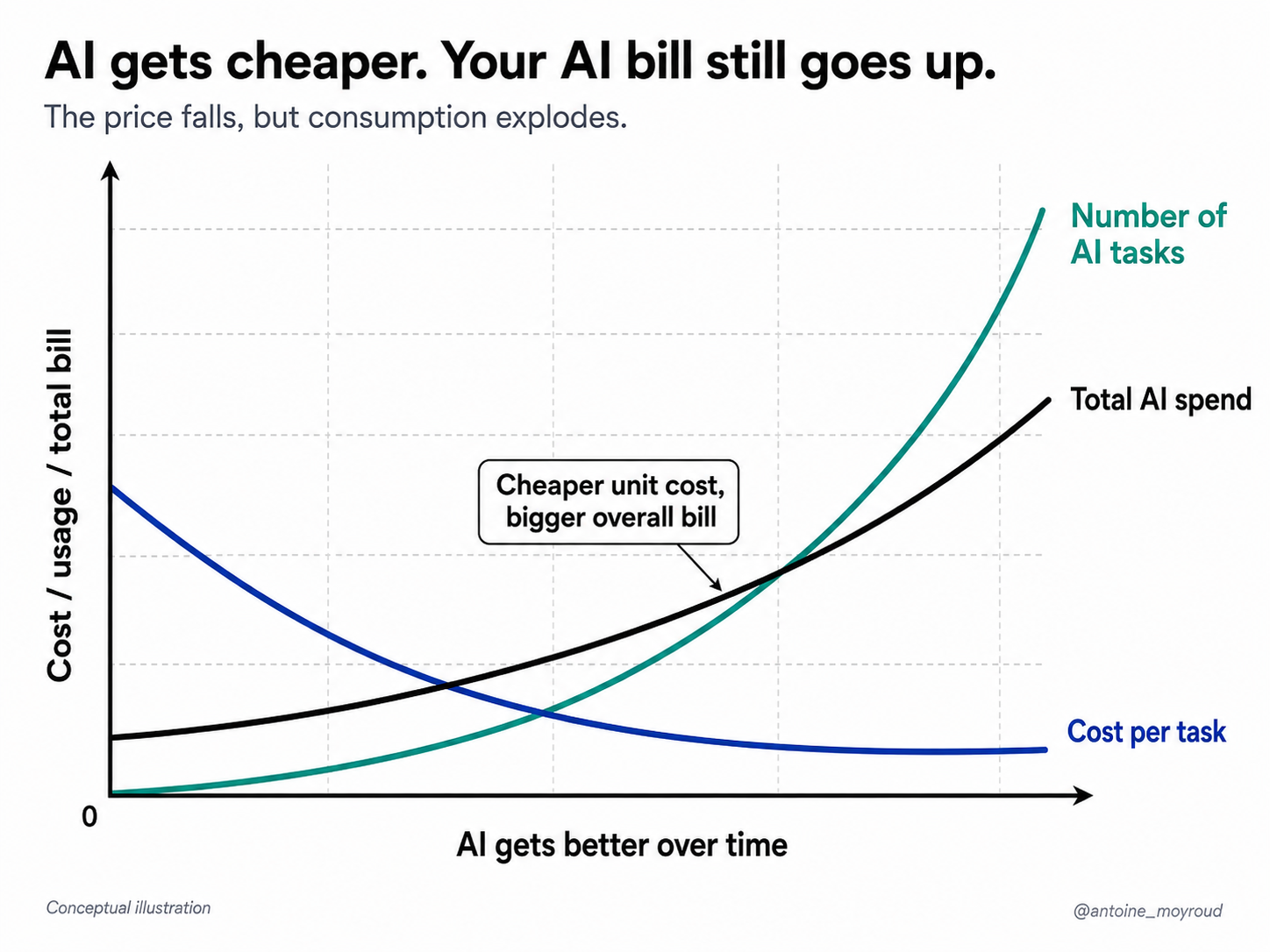
This is why the whole conversation around the ballooning AI bills is such a good signal. I don't think it's telling us that intelligence is expensive.
In many ways the opposite is happening. Per-token pricing for a fixed level of capability has collapsed. Open-source models now match what was frontier not long ago. Small models are getting harder, better, faster, stronger.
The floor is dropping toward free but, somehow, the bill keeps growing. That's the interesting part.
The bill
The ballooning bills tell me that we're still spending intelligence the old way.
We went from chat tools to long-running agents with memory, tools, sandboxes, orchestration and access to company context. The token is no longer the product. The token is the current running through the product.
A frontier answer today is a whole harness. Context, memory, retrieval, tools, permissions, data access, execution, evaluation, retries and workflow.
The stack got more powerful so we started pointing it at everything. It's the PhD problem all over again, except now we hired a whole bench of them and put them full-time on expense reports.
It's tempting to read the exploding AI bill as the end of the subsidy era. I think that's partly true but also less interesting than the structural point.
Companies are not overspending on AI only because models are expensive. They're overspending because they are still organizing work as if intelligence came in human-sized bundles.
They're taking workflows designed for employees and pushing unbundled machine intelligence through them. They're taking budgets designed around headcount and trying to map them onto an intelligence that can be summoned, scaled, routed, dismissed and recombined task by task.
The org was built for a world where intelligence had a payroll number and now intelligence has a marginal cost curve. We still haven't been able to process the implications of that reality at the level of organisations. I take as an example the fact that everyone can tell you they are feeling more productive with AI but few can speak confidently to the collective productivity gains across their orgs.
Visibility is how we start, not where we end
This is why the first answer will naturally be "spend visibility". The good old "you can't measure what you don't track".
Sure, that answer is useful. You'll want dashboards, an understanding of which team is burning tokens. You want to know when a workflow suddenly gets expensive. You want routing, budgets, alerts, policy and all the bells and whistles that make finance teams sleep at night.
In the current human-org model, visibility is how we get understanding. Take the human work organisations (teams, functions, managers, tools) and smack an observability layer on top. We ask who is spending, where they are spending, which models they are using, which tasks are expensive and which teams are outliers. That's the right first move. You can't redesign what you cannot see.
Ramp has been framing this as work moving from labor to capital, which feels directionally right. Great, thanks to observability tooling, you now see where the spend is flowing across your employees and agents. You gradually start having a better understanding of your organization's consumption of intelligence. It doesn't, by itself, reinvent that consumption though.
The deeper question isn't just "how do we monitor AI spend?", it's "how should an organization consume intelligence in a world where humans and agents coexist?"
A company organized for task-level intelligence looks different from a company organized around job descriptions. It doesn't just allocate people to teams to carry out jobs. It allocates different levels of intelligence to those jobs after having understood the clear set of tasks that, together, successfully complete a job.
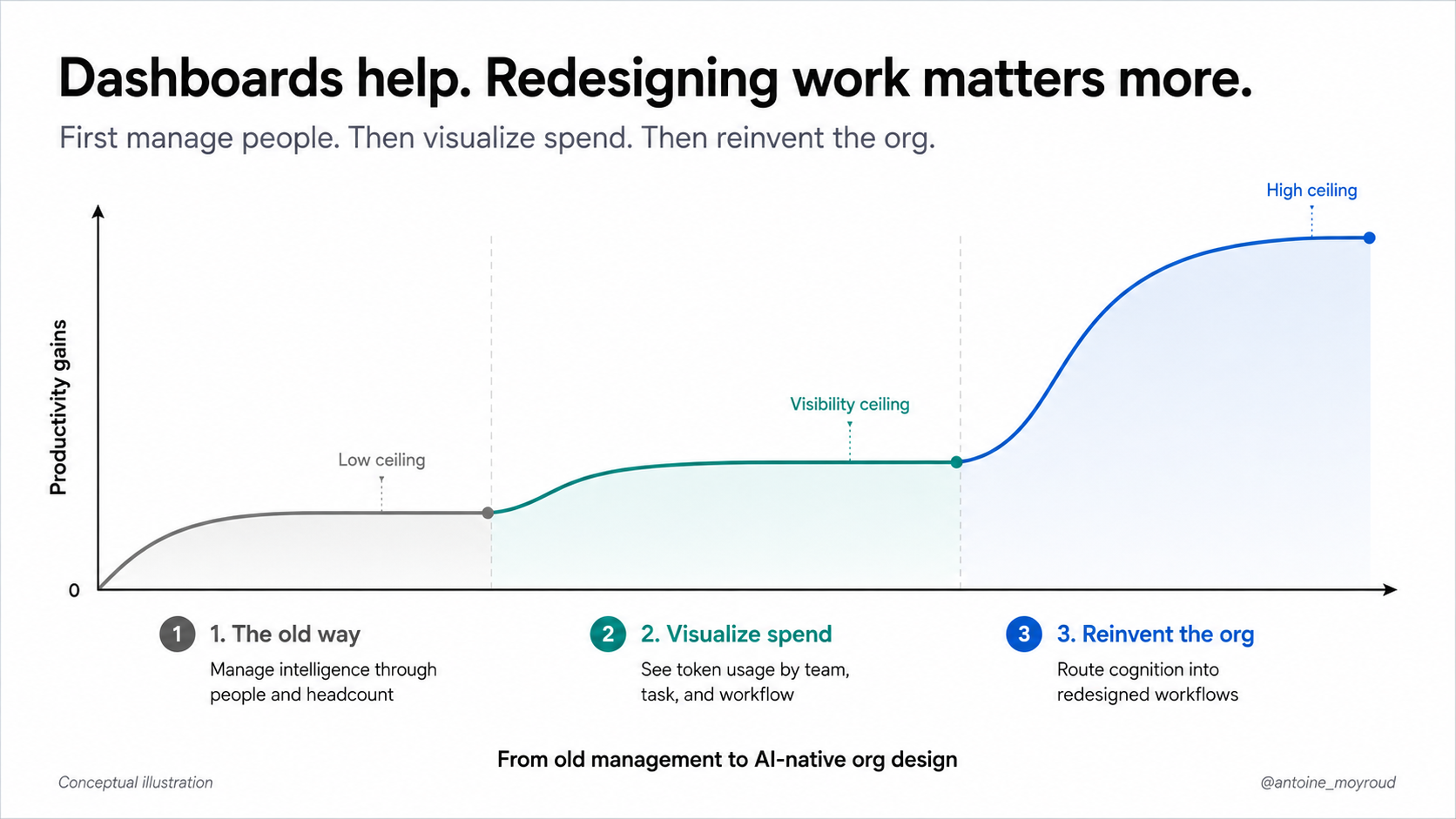
Over time, the org chart starts to matter less than the intelligence routing layer underneath it.
That sounds abstract but it will become very concrete.
Every workflow will need an answer to a new set of questions.
- What is the cheapest intelligence that can do this reliably?
- When should the system escalate?
- What context does the task need?
- What tools should it be allowed to use?
- What is the cost of being wrong?
- What is the value of getting it right?
- Who is accountable when the machine does the work?
These are not developer, infra or model selection questions. They're management questions. Model routing is only the first primitive. The real frontier is routing work.
The new unit of management
The unit of management used to be the person.
Then, for a while, software made us think the unit was the seat. SaaS priced the organization as a collection of users. Every employee got a login. Every team got a tool.
AI breaks that too. The unit is no longer the seat. It is the task.
If the task is the unit, then pricing changes. A hiring plan starts to look like a capital allocation plan but in the deeper sense that the company is deciding where to deploy intelligence.
- Some work should be done by humans.
- Some work should be done by agents that can act.
- Some work should be done by cheap models.
- Some work should be done by expensive models.
The companies that get this right will be the ones that learn how to decompose work into the right cognitive units.
They will know when to use the intern, when to use the PhD, when to use the frontier model, when to use the small model.
That's what I currently view as the actual productivity frontier. Not tokenmaxxing, not "use AI everywhere", not "cut headcount". Doing the hard work of learning how much intelligence each task needs.
Where this goes
My suspicion is that spending on frontier intelligence will not flatten.
The commodity overspend will come down. The 8 prompts that never needed the frontier will get routed away. The dumb uses will become cheaper. The picker will disappear. Users will stop choosing models manually because choosing models is annoying and the system will quietly send easy tasks to smaller models.
The floor drops toward free and the ceiling keeps moving.
Every time cheaper models absorb yesterday’s hard tasks, frontier models open up a new class of work that was not previously possible. The organization does not simply bank the savings. It finds new things to do.
It's not just that we keep finding new and harder work for the frontier to do. Test-time compute turned the best answer from a fixed ceiling into a dial. You pour more compute into a single hard problem at inference and you get a better answer and so far nobody has found the bottom of that. Noam Brown put it precisely in his latest blogpost.
On the hardest problems, "we may not observe a plateau at all within practical budgets," and the better the model gets, the further out that plateau moves. We likely don't even know the ceiling of today's models because measuring it is too expensive.
Put ten million dollars of inference into a single task and you could get answers no human and certainly no cheap model could reach. The smartest output used to be capped at the smartest person in the room and now it's capped at how much you're willing to spend on a single answer.
The ability to decide on which are the problems that matter and deserve the most compute is increasing and for those problems that matter, people will spend.
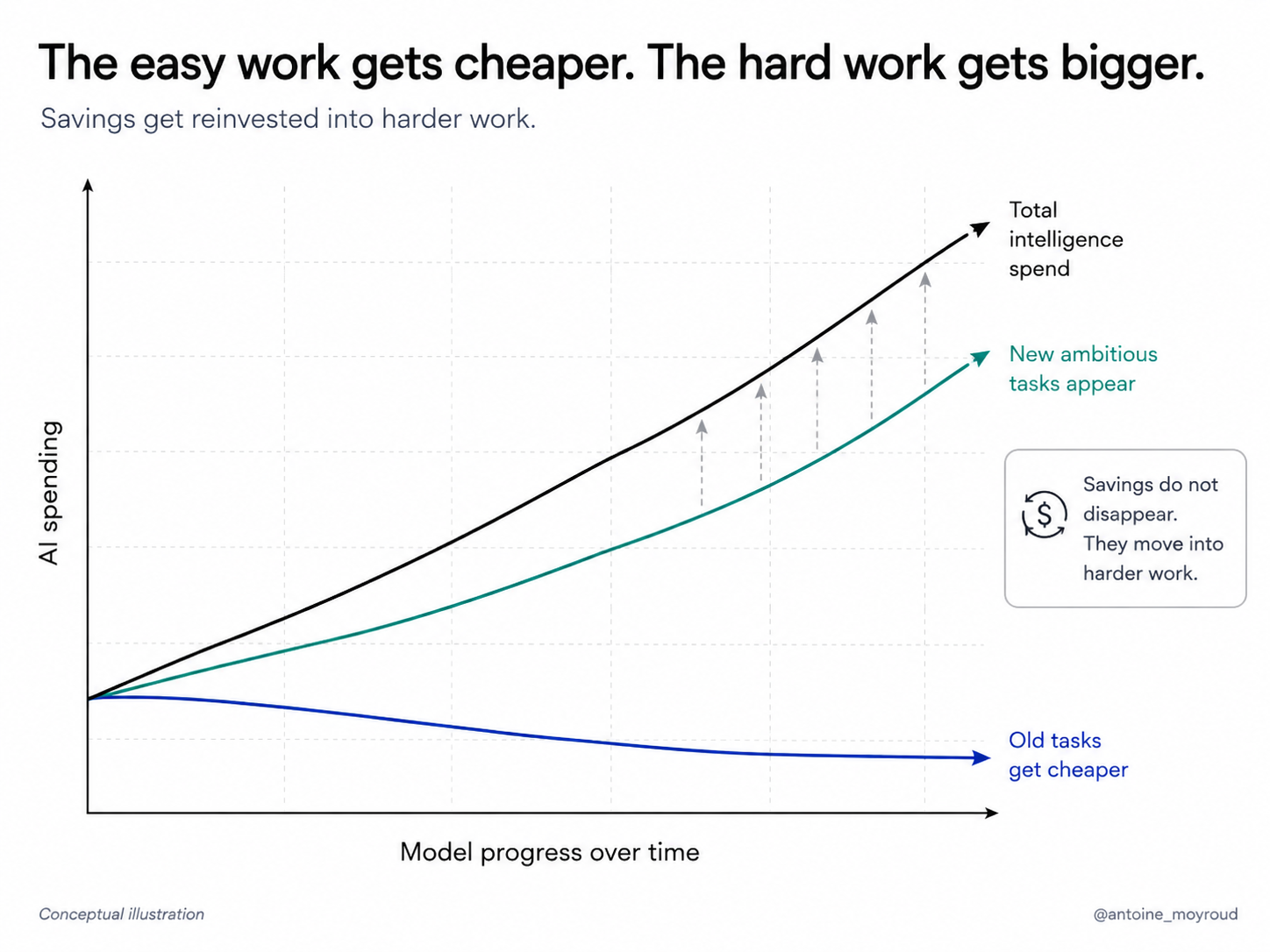
White-collar work didn't get cheaper in aggregate just because individual tasks were automated. The work climbed to meet new capabilities. People used the gains to do more with less or to do much more with more.
We'll go through this with AI too. The easy tasks will get commoditized. The hard tasks will get more ambitious. The definition of “hard” will move up.
The TL;DR is that it's not just a spend and cost story. It's a reorganization story.
Tyler Cowen gets to the same conclusion from the altitude of GDP in his latest presentation at the Sana AI summit a few weeks back. He expects AI to boost US GDP growth from 2% to 2.5%. So why only 0.5% increase if AI is so great?
"The smarter the AI is the harder it is for you to work with it and the harder it is for organisations to adopt it."
"The time gained isn't being converted into higher productivity because the organisations haven't evolved to take those gains and have them make each other more productive"
The impact of AI on growth looks modest, not because it isn't powerful but because of the time it takes for companies to figure out how to digest it organizationally.
We're not bottlenecked on intelligence, we're bottlenecked by the way we have organized ourselves to use it.
The models are increasingly ready. We are not, yet!